I’ve become a fan of using named parameters for adding expressiveness to code that could otherwise be ambiguous. You could argue that there are better approaches for increasing code readability, but sometimes a named parameter can go a long way. For instance, the intention of the following code is pretty obvious (or should be) to someone reading it:
var grid = new WebGrid(canSort: false,
rowsPerPage: 10)
.Bind(autoSortAndPage: false,
source: data,
rowCount: count);
In the case of the WebGrid’s constructor (and its Bind function), named parameters are typically needed because it contains a handful of optional parameters that you usually don’t override, but ordinaly precede the ones you do (as is the case with my example above). But, even if canSort and rowsPerPage were the only parameters in the WebGrid class’ constructor, I might still name them for clarity. Either way, that’s besides the point.
The nice thing about named/optional parameters is that parameter ordinality no longer matters. You can omit and rearrage parameters within your method calls to whatever is most intuitive for you. For instance, I like the approach the ASP.NET team has taken with their web helpers (e.g. WebGrid), in which they favor large parameter count method signatures where every parameter (or most of them) is optional. That way your calling code can be as simple or complex as you want/need it to be and you can name your parameters and order them however you please.
For instance, when generating the HTML for my above WebGrid, I could simply call:
grid.GetHtml()
Or I could get much fancier and do:
grid.GetHtml(mode: WebGridPagerModes.NextPrevious,
htmlAttributes: new { id = "error-list" },
columns: grid.Columns(
grid.Column(format: @<text>
<a title="View Details" href="Href("@/ErrorLog/" + item.Id)"><span>View Details</span></a>
<a title="Clear" href="Href("@/ErrorLog/" + item.Id)/Delete"><span>Clear</span></a>
</text>),
grid.Column("Time", "Date/Time"),
grid.Column("ExceptionTypeName", "Type"),
grid.Column("Message"),
grid.Column("Cookies?", format: @DisplayYesNo(item.Cookies)),
grid.Column("Form?", format: @DisplayYesNo(item.Form)),
grid.Column("Query?", format: @DisplayYesNo(item.QueryString))))
All of this works great and is a pretty slick pattern for doing these kind of “helpers”. But, a wrench gets thrown into the works when using this pattern in a very specific scenario: if your method takes a generic delegate (e.g. Func<T>, Action<T>) as a parameter, and you’d like your consumers to be able to leverage type inference.
Let me state that another way: if you have a generic method that takes a generic delegate as a parameter, your consumers have to choose between using named parameters and type inference. Both won’t work in this context.
NOTE: I say “generic method” because if a method took a generic delegate as a parameter, but the generic type was coming from the containing class (e.g. public class Whatever<T>), then type inference on the method wouldn’t be necessary.
To see what I mean, let’s look at an example. Imagine you have the following method (it’s a method for creating an RSS and Atom feed based on some application data):
public static void Register<T>(string rootUrlName, string title, Func<IEnumerable<T>> entryData, Func<T, FeedEntry> entryMapper, string description = "")
Here we’ve introduced generic delegates as parameters to a generic method. We also have an optional parameter. Calling it to create a feed of static People data could look something like this:
Register<Person>("",
"People Feed",
() => new[] {
new Person { FirstName = "Jonathan", LastName = "Carter" },
new Person { FirstName = "Drew", LastName = "Robbins" }
},
(p) => new FeedEntry {
Title = p.FirstName + p.LastName,
Content = "This person needs to be described better!"
},
"This is a feed of people);
We’re explicitly setting the generic type parameter and aren’t using named parameters, so everything works as expected. As the consumer of this method, though, I might decide to use named parameters here, which would then look like this:
Register<Person>("",
title: "People Feed",
description: "This is a feed of people",
entryData: () => new[] {
new Person { FirstName = "Jonathan", LastName = "Carter" },
new Person { FirstName = "Drew", LastName = "Robbins" }
},
entryMapper: (p) => new FeedEntry {
Title = p.FirstName + p.LastName,
Content = "This person needs to be described better!"
});
Notice that I moved the description parameter up in the order, since I find that to be more readable. Named parameters allowed me to do this, and is a small little improvement that I love using sometimes.
Now, I might also decide to “clean” this up a bit further and allow the C# compiler to infer the type parameter. After all it should be smart enough to know, based on the value I’m passing to entryData, that T should be Person. But, if I write the following, I’ll get an error:
Register("",
title: "People Feed",
description: "This is a feed of people",
entryData: () => new[] {
new Person { FirstName = "Jonathan", LastName = "Carter" },
new Person { FirstName = "Drew", LastName = "Robbins" }
},
entryMapper: (p) => new FeedEntry {
Title = p.FirstName + p.LastName,
Content = "This person needs to be described better!"
});
The reason this doesn’t work is because of the fact that I’m using named parameters, type inference and generic delegates all at the same time. If I removed the named parameters from the above, it would work:
Register("",
"People Feed",
() => new[] {
new Person { FirstName = "Jonathan", LastName = "Carter" },
new Person { FirstName = "Drew", LastName = "Robbins" }
},
(p) => new FeedEntry {
Title = p.FirstName + p.LastName,
Content = "This person needs to be described better!"
},
"This is a feed of people");
This proves I can choose between type inference or named parameters, but not both. Unfortunately, you’ll notice that I had to move the description parameter back to the end of the parameter list, because without being able to use named parameters, I can’t rearrange the defined ordinal.
Why is this the case though? Before explaining that, let’s clarify how type inference in general works. When I defined the Register<T> method above, it just so happened that some of its parameters also made use of the generic type parameter T. What that means is that as long as the T can be determined from the parameter value, it can also be inferred for the entire method, which allows us to not explicitly pass it (e.g. Register<T> vs. just Register). If none of the method parameters make use of the generic type parameter then type inference wouldn’t be possible, since the compiler would have no way of determining it.
This is a pretty slick feature, and is why the sample code above works without specifying the generic type parameter explicitly. The lambda that I pass to the entryData parameter tells the compiler that the T generic type parameter should be set to Person. Subsequently, because the next parameter (entryMapper) also makes use of the T generic type parameter, the compiler now knows that T is of type Person, so you’d get intellisense within the lambda.
This type inference behavior works great regardless whether you’re specifying your parameter list ordinaly or named, except when there is a generic delegate parameter. Moreover, even if you pass the parameters in the defined order, but name them, type inference still won’t work (our example above proved this).
There is a slight caveat to this rule, as can be seen below (I’m now omiting the description parameter):
Register("",
"People Feed",
() => new[] {
new Person { FirstName = "Jonathan", LastName = "Carter" },
new Person { FirstName = "Drew", LastName = "Robbins" }
},
entryMapper: (p) => new FeedEntry {
Title = p.FirstName + p.LastName,
Content = "This person needs to be described better!"
});
This proves that named parameters, generic delegates and type inference can kind of work together. If I tried to name any of the first three parameters, though, the code would once again be broken. This clarifies that once the type has been inferred from a parameter value, all subsequent parameters (even generic delegates) can now be named.
NOTE: This constraint only exists for generic delegates. If your generic method takes other generic types (e.g. IEnumerable<T>), you can successfully use type inference and named parameters together as flexibly as you please. It’s only when using generic delegates that you have to choose.
Beyond understanding why this constraint exists, it still provides a limitation for designing a clean/simple API. For instance, I want the Register function to be generic in order to provide intellisense for callers when setting the lambda expression parameters, but I also want it to be used in dynamic scenarios where a type isn’t known (or needed). You could argue that a developer could simply call the method as Register<dynamic>, and you’d be right, but that code seems unnecessary for the consumer. In addition, that doesn’t help in situations where the inferred generic type is an anonymous type and you want intellisense for subsequent parameters, like so (notice I’d get intellisense in the fourth parameter on the p variable):
,
Register("",
"People Feed",
() => new[] {
new { FirstName = "Jonathan", LastName = "Carter" },
new { FirstName = "Drew", LastName = "Robbins" }
},
(p) => new FeedEntry {
Title = p.FirstName + p.LastName,
Content = "This person needs to be described better!"
});
What would the user specify as the generic type here? This is a scenario where type inference becomes very useful. Imagine how nice that code would look with named parameters as well. It’d be beautiful :)
So how could I support the caller for being able to leverage…
- Explicit generic type declaration with named parameters
- Explicit generic type declaration without named parameters
- Generic type inference without using named parameters
- Generic type inference with named parameters
The first three items are already satisfied by our existing Register<T> method, but the fourth isn’t. I could satisfy all four by removing the generic type parameter and changing all occurrences of T in the parameter type definitions to dynamic, but then I’d completely lose intellisense in scenarios where a type could be inferred (that wouldn’t be type inference then). Therefore, how can I allow all four scenarios, without completely giving up intellisense for the developer? Unfortunately, you can’t. Item #4 just won’t work with the current C# compiler. It’s a bug.
Hence, if you’re designing an API that uses generic methods, that take generic delegates as parameters, and you want your users to be able to use type inference (needed for anonymous types), you’ll need to make sure that named parameters aren’t necessary to add expressiveness, since they won’t be usable, unless the parameter that can infer the type is very early on in the method signature’s parameter order. This means that a method with optional parameters (where named parameters become common), that uses generic delegates, can’t take advantage of type inference unless the caller specified every optional parameter and didn’t use named parameters, which is a pretty poor expectation.
Where applicable, a method chaining API (a.k.a. fluent API) could be a great option for creating additional expressiveness for your users without sacrificing any type inference or intellisense. Unfortunately, though, sometimes a fluent API is overkill for a scenario (e.g. a helper function), or less intuitive, so you’re stuck dealing with the named parameters/type inference limitation.
This is a pretty niche limitation (generic method + generic delegate parameter + named parameters + type inference), and probably won’t occur very often for folks designing APIs, but when it does, hopefully this post will help you from wanting to pull your hair out from wondering what the issue is. When all else fails: just explicitly declare your generic type parameters. I’d rather do that than give up named parameters :)
In my last post, I gave an introduction of the WCF Data Services Toolkit and illustrated how it provides a simple abstraction on top of WCF Data Services, which hopefully makes it easier to layer OData on top of arbitrary data sources (e.g. existing web API). For the sake of simplicity, I only showed the read-only scenario-which makes up a large majority of customer needs-but I also need to show how you could also handle updates (POST/PUT/DELETE) within your toolkit services.
Because the toolkit is built on top of WCF Data Services, you could obviously implement IDataServiceUpdateProvider (or IUpdateable) on your data context type (the T in [O]DataService<T>) and be good to go. The “problem” with that approach is that the toolkit encourages your context to be pretty thin, containing little more than your entity declarations (e.g. User) and repository mappings (e.g. User -> UserRepository). Using the toolkit’s repository paradigm, it’d make much more sense to place the update handling within each of your respective repositories, keeping the logic for each entity isolated and simplified.
If you’ve dug around the toolkit bits much, you might have stumbled upon an interface called IWriteableRepository and wondered what it is for. It simply allows you to mark a repository as being capable of handling updates (or writes), and implement a few simple methods to do so: CreateDefaultEntity, Remove, Save and CreateRelation. These map somewhat closely to IUpdateable/IDataServiceUpdateProvider, but live on your repository not your context.
The way this works is that the ODataContext class (which your context type needs to inherit from) is itself an IDataServiceUpdateProvider and will do the translation between that interface and IWriteableRepository, if your repository implements it. So when an update request comes in for a specific entity type, the runtime will ask which repository handles it and pass the request on appropriately. Let’s check out a demo of how this might work. We’ll use the Twitpic OData service (which is implemented using the toolkit) as an example.
Let’s do a quick rundown of the codebase. I have a context type called TwitpicData that inherits from ODataContext. It declares a handful of IQueryable<T> properties and then overrides the RepositoryFor method to map entity types to their respective repository. It looks something like this:
public class TwitpicData : ODataContext
{
private readonly TwitpicProxy proxy;
public TwitpicData(TwitpicProxy proxy)
{
this.proxy = proxy;
}
public IQueryable<Image> Images
{
get { return this.CreateQuery<Image>(); }
}
public override object RepositoryFor(string fullTypeName)
{
if (fullTypeName == typeof(Image).FullName || fullTypeName == typeof(Image[]).FullName)
return new ImageRepository(this.proxy);
throw new NotSupportedException();
}
}
NOTE: There are more entity types in the production service (e.g. User, Tag), but we’re only going to focus on Image, so I trimmed the code down. The TwitpicProxy class that you see is simply the class that knows how to make calls to the Twitpic REST API.
At this point, everything looks the same as examples we saw in the previous post, but interestingly enough, Twitpic’s API allows you to upload images, so the ImageRepository would need to handle writes.
If we look at the repository, in addition to having the expected read methods (e.g. GetOne, GetAll) and foreign property methods (e.g. GetImagesByUser, GetImagesByTag), it also implements IWriteableRepository.
public class ImageRepository : IWriteableRepository
With that in place, the toolkit runtime knows to allow Image writes and who will handle them. Let’s look at the four methods the interface includes, and see how they work in the context of Twitpic.
public object CreateDefaultEntity()
{
return new Image
{
ShortId = string.Format(CultureInfo.InvariantCulture, "temp-{0}", DateTime.Now.Ticks)
};
}
The CreateDefaultEntity method will be called when an add operation (POST) is being performed. All that it needs to do is create an instance of the respective type that puts it in the correct state. For many service implementations this will simply just need to “new up” an instance of the type and return it. In the case of Twitpic, when an Image type is created, we give it a temporary ID that is used to do some back-end correlation (we store the image in Azure blob storage before actually uploading it via Twitpic’s API). The details of that are outside the scope of this post, but suffice it to say, we’re just creating a new Image type that can be filled from the data being sent by the user.
Once the Image type has been created, the runtime will populate its properties with any data that was POSTed by the user. Once it has completed that, it will call the Save method on your repository, which is simply responsible for actually persisting the entity. Twitpic’s looks something like this…
public void Save(object entity)
{
var image = entity as Image;
if (image.Message == null || !image.ShortId.StartsWith("temp-"))
return;
var imageContents = [Comes from somewhere]
this.proxy.UploadImage(imageContents, image.Message, image.ShortId, image.Type);
}
It simply checks that the incoming image has a Message and that its ShortId property starts with “temp-“, signifying that it’s a new image. It grabs the binary content of the updated image (omitted from the post) and then routes the call to Twitpic’s API. Notice the “image.Message” and “image.Type” are now populated. Those values came from the user.
When a user modifies an existing entity instance, CreateDefaultEntity obviously won’t be called, but Save will. It’s up to you to determine whether the entity passed to the Save method is being added or deleted. Twitpic doesn’t support image updates so we don’t need to worry about that here.
When the user deletes an entity instance, neither the CreateDefaultEntity or Save method will be called. Instead, the Remove method will be called, passing you the instance being deleted.
public void Remove(object entity)
{
throw new NotImplementedException();
}
Twitpic doesn’t allow you to delete an image, so this repository doesn’t make use of it, but you can imagine how simple it’d be to pass the deletion on to your underlying data source.
The final method to implement on the IWriteableRepository interface is CreateRelation. This is called when the user adds a relation between two entity types, such as adding a Comment to an Image.
public void CreateRelation(object targetResource, object resourceToBeAdded)
{
var image = targetResource as Image;
var comment = resourceToBeAdded as Comment;
comment.Image = image;
this.proxy.CreateComment(comment);
}
The method simply takes a Comment (the resource being added), associates it with an Image (the target of the relation), and passes it on to the Twitpic API.
That’s it. Now we have an OData service that provides users with read and write operations of Twitpic images, and adding the write functionality only took about 20 lines of trivial code (aside from the Twitpic specific code). The service could now be consumed using the WCF Data Services client or any other OData/HTTP consumer that knows how to perform write operations.
If you read through this post and thought: “Hey, where is all the meat of the write operations? You kept showing this Twitpic proxy thing but didn’t actually go into the code”, I’d respond with: “Exactly”. My whole objective with the toolkit is to handle as much of the infrastructure/OData plumbing as possible and let you focus on the portion that you know best: communicating with your underlying data source. Chances are, you know your data really well, and so as long as we give you the right hooks, and make it easy, your job shouldn’t be too bad.
NEXT STEPS: While I think this is pretty simple, there is room for improvement in numerous areas. For instance…
- CreateDefaultEntity should be optional since many implementations will only be creating a new instance.
- The current IWriteableRepository interface isn’t generic so all the method parameters are of type object. We could make a generic version but that wouldn’t help with the CreateRelation method, since the “resourceToBeAdded” could be numerous different types.
- I ultimately want to remove IWriteableRepository and make the write methods discoverable via conventions, the same way the read methods are. This would solve the above two issues and also allow you to have multiple CreateRelation methods (e.g. CreateCommentRelation, CreateTagRelation).
I’m doing a session on the toolkit at MIX in a few weeks and would love to chat with folks using it or looking to use it. Please don’t hesitate to send any feedback or comments my way.
This morning we released a project that we’ve been cranking on for a while that is affectionately called the WCF Data Services Toolkit. You can download it here (or pull it down via NuGet using the “WCFDataServicesToolkit” ID), and also get a description of exactly what it is/does. Go read the release notes if you want a deeper explanation, otherwise carry on.
In a nutshell: the WCF Data Services Toolkit makes it easier for you to “wrap” any type of data (or multiple data sources) into an OData service. In practice, many people have done this with existing web APIs, XML files, etc. As mentioned on the Codeplex page, this toolkit is what is running many of the OData services out there (e.g. Facebook, Netflix, eBay, Twitpic).
Because the OData consumption story and audience is pretty deep, having data exposed via that protocol can provide a lot of benefits (even as a secondary API option) for both developers and end-users. If compelling data exists, regardless what shape and/or form it’s in, it could be worthwhile getting it out there as OData, and the toolkit strives to make that process easier.
For example, if you have interesting data already being exposed via a web API, and you’d like to layer OData on top of that (perhaps to prototype a POC or get feedback from customers without making a huge technical investment), you would have a lot of work to do in order to get that working with the currently available bits. With the WCF Data Services Toolkit it’d be reasonably simple*. To illustrate how this would look, let’s take a look at an example of how to build such a solution.
* Knowledge of WCF Data Services and overall web APIs is still required.
One of my favorite products as of late is Instagram. They’ve traditionally been solely an iPhone product, but they’ve fully embraced the “Services Powering Experiences” mantra and released an API so that other clients can emerge, making them a service provider, not just an iPhone application developer. I’d love to see what it would look like to have an OData version of that API, so we’ll use the toolkit to proof that out.
Step #1: Define your model
The Instagram model includes entities like Media, Location, Tags, etc. but we’re going to keep things simple and just focus on the User entity from their API. Obviously, a User is someone who has signed up for Instagram and can submit images, follow users, and also be followed by other users. A simple C# declaration of that entity could look like so:
[DataServiceKey("Id")]
public class User
{
public string Id { get; set; }
public string UserName { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public User[] Follows { get; set; }
public User[] Followers { get; set; }
public string AvatarUrl { get; set; }
}
Notice that I’m specifying navigations (e.g. Follows, Followers) as simple CLR properties, which makes it easy to define relationships between entity types. Also note that I’m using the DataServiceKeyAttribute (from WCF Data Services) to declare what my key property is. [Every entity type in WCF Data Services has to have a key, for obvious reasons]. This should all be very intuitive so far.
Step #2: Define your context
Once you have your entity types, you need to define your context, that declares the name and types of all collections your OData service will expose. This concept isn’t new to the toolkit, so it shouldn’t come as a surprise. The only difference here is where your data is coming from.
public class InstagramContext : ODataContext
{
public IQueryable<User> Users
{
get { return base.CreateQuery<User>(); }
}
public override object RepositoryFor(string fullTypeName)
{
if (fullTypeName == typeof(User).FullName)
return new UserRepository();
return null;
}
}
Notice that my context is derived from ODataContext which is a special class within the toolkit that knows how to retrieve data using the “repository style” we’ll be using here (more later). I declare a collection called “Users” that will return data of type User that we defined above. We don’t have to worry about how to create an IQueryable that actually handles that (very complex task), but rather we can use the CreateQuery method of the ODataContext class.
Where the actual “magic” happens is within the RepositoryFor method that we overrode from the ODataContext class. This method will be called whenever a query is made for data of a specific type. In our case, whenever a query is made for User data, we need to return a class to the runtime that will know how to actually get User data. Here we’ve called it UserRepository.
Step #3: Define your repository
The toolkit expects you to give it a “repository” that will actually serve your data. The word “repository” here is used in the loosest sense of the term. All it really needs is a class that follows a couple simple conventions. Here is what the UserRepository class could look like:
public class UserRepository
{
public User GetOne(string id)
{
var url = "https://api.instagram.com/v1/users/" + id + "?client_id=" + InstagramSettings.ClientId;
var client = new WebClient();
var userString = client.DownloadString(url);
var user = Json.Decode(userString).data;
return new User
{
Id = user.id,
UserName = user.username,
FirstName = user.first_name,
LastName = user.last_name,
AvatarUrl = user.profile_picture
};
}
}
Note: The InstagramSettings.ClientId property is simply my registered application’s ID. I’m omitting the actual value so as to not get bombarded with calls from anyone besides me.
Notice that this is a POCO class (no base class or attributes) with a single method called GetOne. This method will be called by convention (doesn’t need to be wired up anywhere) by the runtime when a request is made for a specific User, such as /Users(‘55’). To make matters even simpler, our method can declare the key parameters that will be passed in, that way we don’t have to deal with the actual HTTP request, and more importantly, any of the expression tree that is built from the OData request. We simply are given an ID and asked to return a user.
To do that, I make a very trivial call to the Instagram API, decode the JSON, and re-shape it into my version of the User entity. And that’s it. A handful of boilerplate code, and some basic knowledge of the Instagram API and I’ve got a basic OData service wrapping their data.
Step #4: Define your service
Now that we have our entity, context and repository, we just need to define our OData service that will be the actual endpoint for users to hit. Once again, this is a purely WCF Data Services concept, and the code will look identical to what you’d expect.
public class InstagramService : ODataService<InstagramContext>
{
public static void InitializeService(DataServiceConfiguration config)
{
config.SetEntitySetAccessRule("*", EntitySetRights.All);
config.DataServiceBehavior.MaxProtocolVersion = DataServiceProtocolVersion.V2;
}
}
The only point of interest here is that we’re deriving from ODataService<T> and not DataService<T>. ODataService<T> is a supertype of DataService<T> and provides a handful of functionality on top of it (e.g. JSONP, output caching). It’s part of the toolkit, and you don’t have to use it, but you mine as well since you’ll get more features.
With this code in place, if I run my service and hit the root URL, I’ll get the following:

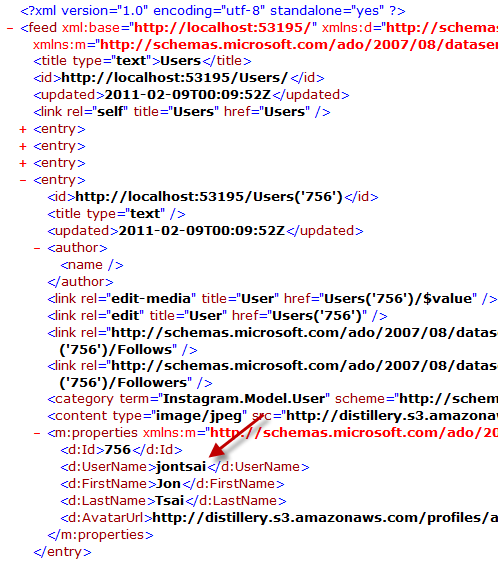
Notice my Users collection as expected. If I request a specific User by ID (/Users(‘55’), then I should get back that User (trimmed):

I can also request a specific property for a User like always (/Users(‘55’)/FirstName or even /Users(‘55’)/FirstName/$value) and that will work too.
Great, now let’s add the ability to get multiple users (as a feed) in addition to just one user. To do this, let’s add another method to the UserRepository class, once again following a simple convention.
public IEnumerable<User> GetAll(ODataQueryOperation operation)
{
if (!operation.ContextParameters.ContainsKey("search"))
throw new NotImplementedException("Users cannot be enumerated, they can be accessed by using the User's ID. e.g. /Users('55') or by providing a 'search' query string.");
var searchString = operation.ContextParameters["search"];
var url = "https://api.instagram.com/v1/users/search?q=" + searchString + "&client_id=" + InstagramSettings.ClientId;
var client = new WebClient();
var usersString = client.DownloadString(url);
var usersJson = Json.Decode(usersString).data;
var list = new List();
foreach (var user in usersJson)
list.Add(ProjectUser(user));
return list;
}
Instead of GetOne, the convention for retrieving a feed of entities is to create a method called GetAll. This method could take no parameters, but to illustrate another feature of the toolkit, I’ve declared a single parameter of type ODataQueryOperation. This is a simplified view of the incoming OData request (e.g. filters, ordering, paging) that is constructed for you to easily “reach into”, once again, without having to parse the URL or deal with any expression trees. Just by declaring that parameter, we’ll now have access to all of that data.
Because retrieving a list of all users wouldn’t be very useful (or practical), if a request is made for th Users feed, we’ll return an error saying that isn’t allowed. What we do allow though is for a search criteria to be specified, at which point, we’ll pass that search string to the Instagram API, and then project the returned JSON response into our User entity type. The code is virtually identical to our GetOne method.
If we re-run the service and hit the Users feed (/Users), we’ll get an error as expected. If we add a search criteria though (/Users?search=jon), we’ll get back a feed of all users with “jon” in their username, first name or last name.
Note: The search semantics we’re using here isn’t specific to OData, it’s a feature we added onto the service. Because the toolkit provides the ContextParameters dictionary in the query operation, we can easily grab any “special” query string values we allow our users to provide.
Up to this point we’ve only worked with scalar properties, which is interesting, but not nearly as cool as having rich navigations. OData really shines when exposing hierarchical data, such as the association of a User being able to have a list of followers and be able to also follow a list of users.
The Instagram API doesn’t return that associated data when you request a user, so you’d have to call another service endpoint. In order to let the WCF Data Services Toolkit runtime know that an entity association requires “special” treatment, you need to annotate it with a ForeignPropertyAttribute, like so:
[DataServiceKey("Id")]
public class User
{
// Other properties omitted for brevity...
[ForeignProperty]
public User[] Follows { get; set; }
[ForeignProperty]
public User[] Followers { get; set; }
}
What this tells the runtime is that these two properties can’t be satisfied by the request for their parent, and therefore when a request is made for either the Follows or Followers property, they need to be retrieved from another mechanism. Once again, following a convention, we can add two more methods to our UserRepository class to satisfy these navigations:
public IEnumerable GetFollowsByUser(string id)
{
var url = "https://api.instagram.com/v1/users/" + id + "/follows?client_id=" + InstagramSettings.ClientId;
var client = new WebClient();
var usersString = client.DownloadString(url);
var usersJson = Json.Decode(usersString).data;
var list = new List();
foreach (var user in usersJson)
list.Add(ProjectUser(user));
return list;
}
public IEnumerable GetFollowersByUser(string id)
{
var url = "https://api.instagram.com/v1/users/" + id + "/followed-by?client_id=" + InstagramSettings.ClientId;
var client = new WebClient();
var usersString = client.DownloadString(url);
var usersJson = Json.Decode(usersString).data;
var list = new List();
foreach (var user in usersJson)
list.Add(ProjectUser(user));
return list;
}
Notice the fact that the methods are named GetFollowsByUser and GetFollowersByUser. This follows the convention of “Get”[NavigationPropertyName]”By”[EntityTypeName]. Hence, if we renamed the Follows property to Foo, the runtime would look for a repository method called GetFooByUser. You can override those conventions by supplying some parameters within the ForeignPropertyAttribute. You can play around with that, but we won’t go into it here.
The code within these two new methods are once again using the exact same mechanism for retrieving data from the Instagram API, and are once again not having to deal with any of the complexity of URL or expression tree parsing. In fact, both methods easily take the user ID as a parameter, just like the GetOne method worked.
If we now make a request for a user’s Follows navigation property (/Users(‘55’)/Follows), we’ll get back a list of all users that they are following. In addition, we could request the user’s Followers navigation property (/Users(‘55’)/Followers) and get back a lost of all users that are following them.
At this point you could start doing wacky stuff (Users(‘55’)/Followers(‘942475’)/Followers/$count) and hopefully you’ll be impressed by the fact that it all works :)
The last thing I want to illustrate is how to mark an entity type as having a non-textual representation (e.g. an image avatar) that can be retrieved using the $value semantics. To do this with WCF Data Services you have to define a specific IDataServiceStreamProvider and register it with your data service class. It isn’t terribly hard, but if you have a URL for the image (or whatever file type) and you just want to tell the runtime to serve that, the experience should be a lot simpler.
[DataServiceKey("Id")]
[HasStream]
public class User : IStreamEntity
{
// Other properties omitted for brevity...
public string AvatarUrl { get; set; }
public string GetContentTypeForStreaming()
{
return "image/jpeg";
}
public Uri GetUrlForStreaming()
{
return new Uri(AvatarUrl);
}
public string GetStreamETag()
{
return null;
}
}
Here we’ve added the standard HasStreamAttribute to the entity that is required by WCF Data Services to mark an entity as having a non-textual representation. The magic comes in when we implement the special IStreamEntity interface (from the toolkit). The interface simply has three methods: one to tell the runtime what context type you’re using (could be dynamic), one to tell the runtime what the URL is for your non-textual representation, and one to specify an optional e-tag (for caching purposes.)
In our case, we’re simply specifying that the AvatarUrl property of the User should be used to provide the non-textual representation, and that the content type is “image/jpeg”. Now, if a user requests a User entity’s $value (/Users(‘55’)/$value), they’ll get their actual avatar image like so:

Hopefully this illustrates how to begin using the WCF Data Services Toolkit. There is a lot more we can do here, and many more features of the toolkit that can make your OData needs simpler. I’ll talk about more advanced scenarios in future posts such as OAuth intergration, accepting updates (POST/PUT/DELETE), and overriding conventions. Reach out if you have any question/concerns/comments.
One of the most pervasive enemies of software developers is friction in their technology choices. Few things can kill morale quite like the frustration of a framework being completely unintuitive or downright overly complicated. That said, how do you differentiate between something being unnecessarily complex, and just complex? After all, there are difficult and abstract concepts in this field that require knowledge and experience to grasp. A recent run-in with Geico made me ponder where the tipping point is between acceptable and unacceptable complexity.
I recently decided to reevaluate my budget to see where I could trim some fat in order to put more into savings (I’m not getting younger after all). Part of that included me looking around at competing car insurance companies (I’ve been with Geico for ~5 years) to see what kind of rates I could get. After getting some quotes, it turned out I could get the exact same coverage, with another company, but for $50 less a month. Not a huge savings, but it adds up when combined with other budget cuts.
I decided to call Geico to give them the chance to keep my business before jumping ship. I politely told them the savings I could get, and asked them to match it. Unfortunately they couldn’t discount my policy any more than $7 a month (still $43 a month more than a competitor). What really frustrated me though is that they insisted on continuously telling me about services that Geico offers that supposedly merit their higher rates, and that I should stick with them because of them. None of the services they rattled off were actually beneficial to me though, and therefore didn’t warrant the extra cost.
This mentality that superflous features can merit extra costs is absolutely ridiculous, and I refuse to be talked to like I’m an idiot. In the case of your personal budget, the highest order bit is money. You want to get exactly the service you need and pay as little for it as possible. As soon as a company forgets that and tries to trick you into thinking you need something else, they have failed you and society as a whole.
The same principal is very much true when it comes to technology, but in this case, the highest order bit is simplicity, not money*. Therefore, when selecting a technology to use, you should focus on finding something that gives you exactly the functionality you need, and is as simple to use as possible. Sadly, many framework developers/companies forget this and try to contrive value propositions based on unnecessary use cases and features that are supposed to make the overcomplexity merited somehow.
* There is a HUGE caveat to this statement that revolves around scenarios where money is the highest order bit, and it isn’t simplicity your searching for, it’s a consumer base. The two best examples of this are Facebook and the iPhone. Both have traditionally had horrible developer experiences (Facebook is vastly improved these days), but people put up with it because of the monetary opportunities. Ultimately, it’s usually always about money, but in non-consumer facing development, time is money, and therefore simplicity is what creates savings.
Another flaw that framework developers can make is assuming that people will be compelled by “soon to come” features. If simplicity is needed now, then only the alpha geeks will put up with friction when promised something better in the future. When a product determines what its core value prop/usage scenario is, it needs to do that very well, otherwise it’s existence is straddling irrelevance. If the scenario isn’t contrived, then someone else will come along and make it easier to solve in less time.
I’m by no means saying that a project should stay in development until it is “perfect”, leading to a perpetual beta. At some point you have to make a release. But, a release should have an objective, and if it hasn’t reach that objective yet, then releasing it would be completely pointless and a waste of adopter’s time.
Geico also made this flaw, by telling me that in about a year, a speeding ticket would fall out of the grace period and I could be offered a “good driver’s discount”. As mentioned before, the priority here is monetary savings, not longterm loyalty to a company who can make me future promises. There’s nothing stopping me from switching company’s (and saving money) and coming back to Geico in a year when I’m elligible for the discount. This is another example of how they assume I must be an idiot.
There are so many times when I decide to evaluate a framework for use in a software project and I feel almost insulted by how ridiculously unintuitive it is. Either it’s too hard to use because it tries to solve every issue known to man, or it doesn’t seem to actually understand how to solve the problem it’s seeking to, therefore coming off as very immature. In either case, I have zero patience for it, and neither should any developer.
So, how can you tell if a framework isn’t suffering from the “Geico Effect”? Try asking yourself these two questions:
- Does the technology provide a simple to use solution for a real problem without being overcomplicated by superfluous features?
- Does the technology completely solve the problem at the time of use?
If you can comfortably answer yes to both questions, then the technology you’re using is most likely pretty solid, and is being developed by someone who actually gets their audience. If complexity exists with the product, then it is most likely a necessary evil, as few things in life are actually dead-simple.
If you can’t answer yes to those questions, and you’re using a non-beta product, then you’re probably better off moving on, and saving yourself some precious time and sanity.
I’ve owned the domain lostintangent.com for coming on four years, and it has served as my metaphysical home on the Internet for my random thoughts and technology-centric ramblings. Well, that all came to an end a week ago.
My good friend and colleague, James Senior, was tinkering around on my dedicated server (that housed my blog) and needed to install MySQL to support a WordPress instance he was setting up. In the process, he decided to uninstall the old version of MySQL that was already present on the box, so as to have a fresh start. Unfortunately, he didn’t realize that MySQL was the backing store for my blog, and therefore he killed years of my posts in one fell swoop. I love you too James!
This ordeal was actually a great forcing function for me to reboot my blog and my style of writing. I’d gotten pretty tired of the typical “Intro to X” technology post, and have become much more passionate around writing articles that have longer/deeper value than just how to do a couple of non-trivial software tricks.
So, I’ve decided to stop hosting my own blog and join Tumblr. It’s way simpler, and I’m pretty uninterested in maintaining any software (e.g. a blog) that doesn’t solve unique problems. This blog will serve as my technical-centric thoughts moving forward, and brokentheglass.com will serve as my non-technical counterpart.
I’m going to try to keep the focus on topics that are broadly relevant to software development in general, and not specific to a single language and/or framework. I’m much more interested in paradigm shifts and new ways of thinking then in how a particular programming model is a better than another.
Stay tuned…
